The Bioinformatics Triangle: Memory, Elegance, and Speed 🧬
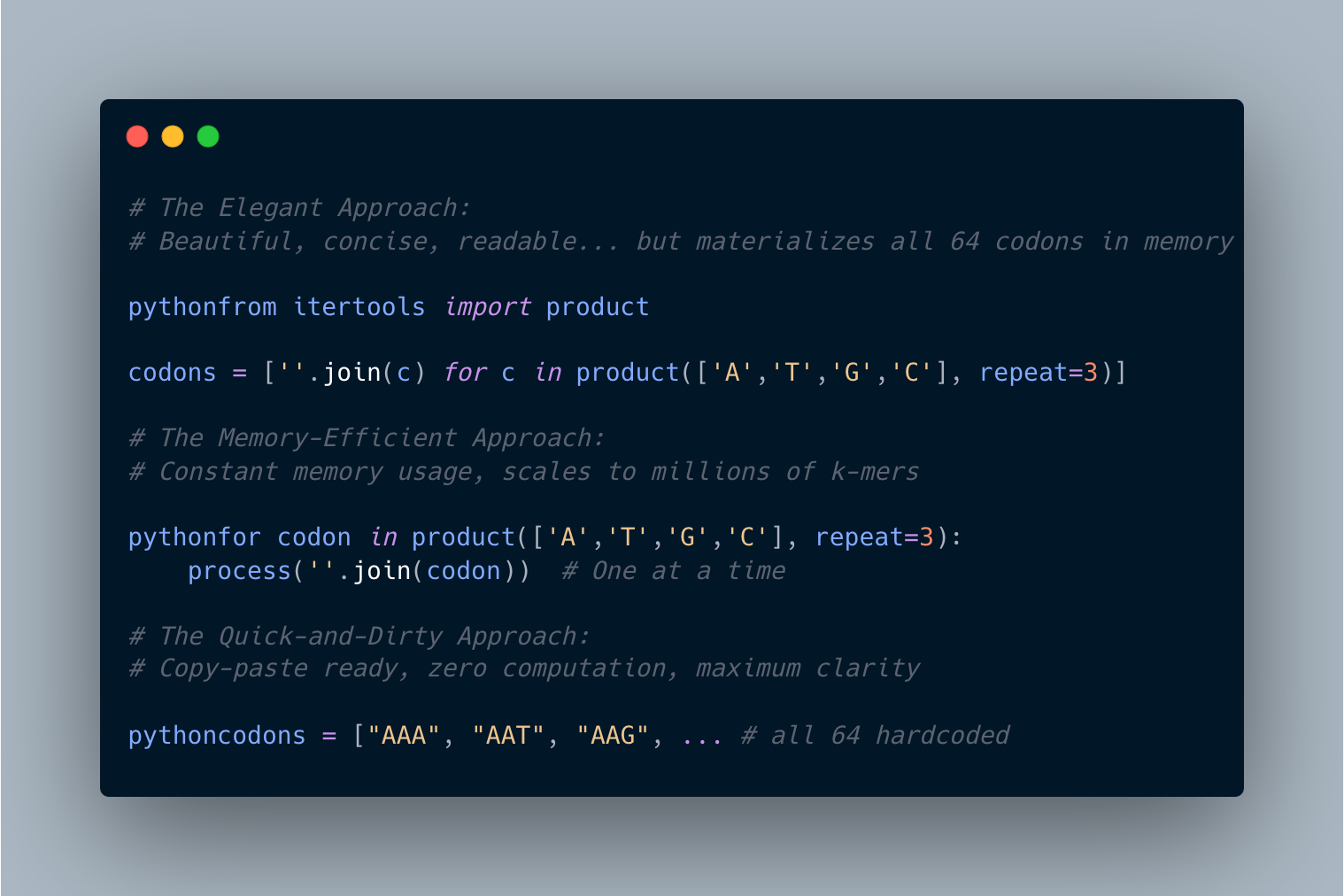
Just had a fascinating discussion about generating all 64 possible codons in Python. Three approaches emerged:
1️⃣ The Elegant Approach: Beautiful, concise, readable… but materializes all 64 codons in memory
2️⃣ The Memory-Efficient Approach: Constant memory usage, scales to millions of k-mers
3️⃣ The Quick-and-Dirty Approach: Copy-paste ready, zero computation, maximum clarity
Here’s the thing: in bioinformatics, we’re constantly juggling massive datasets (think whole genomes), complex algorithms (phylogenetic trees, alignment scoring), and tight deadlines (grant applications, paper submissions).
For 64 codons? Any approach works fine. For analyzing all 15-mers in the human genome? That elegant list comprehension will crash your laptop. 💥
The real skill isn’t picking the “right” approach—it’s knowing when each approach fits. Sometimes you need the generator for scalability. Sometimes you need the hardcoded list for reliability. Sometimes you need the elegant one-liner for a quick analysis.
Where do you fall on this spectrum? Are you team “premature optimization is evil” or team “memory efficiency from day one”? How do you balance code aesthetics with performance in your bioinformatics workflows?